图解unsortedbin attack & largebin attack

(。・ω・。)
malloc 时,不仅仅是从 bin 里面找到并分配合适的内存,还有拿出后重新组织链表,这两种攻击都是在组织链表的时候被改写过的指针骗了,把一块不存在 bin 里的内存当作 free 过后的 chunk 一样组织进去。那么这块内存上就会记录指向 bin 的链表头之类的指针,也就是一个地址,仅当成数据的时候就是一个大数。
unsortedbin attack
unsortedbin 结构
unsortedbin是双向循环链表,FIFO,也就是后进的 chunk 会被组织进“表头”和上一个进入 unsorted bin 里的之间
就像这样: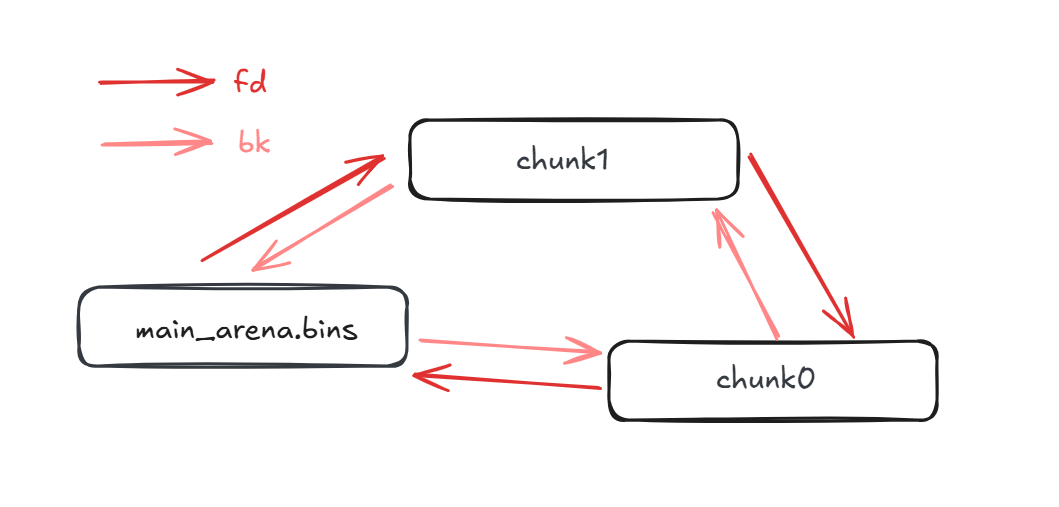
为了循环的结构看的更加清楚,我把它画成了圈的形式,chunk0 是先被 free 的堆块。
往 unsortedbin 里面打两个 chunk 的话也可以看到他的结构是这样的。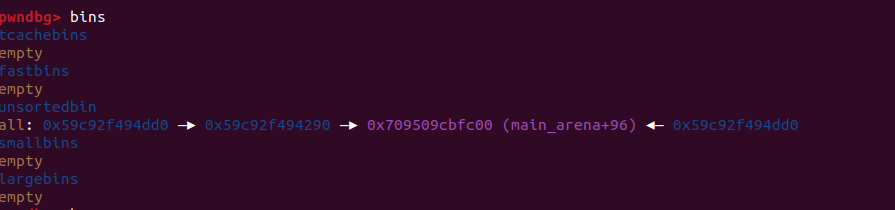
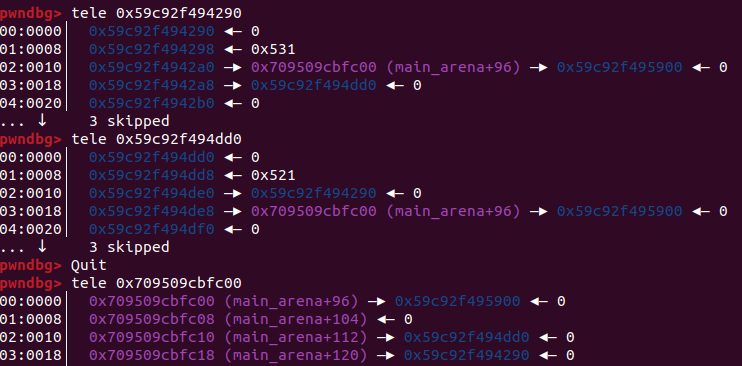
源码分析
然后看源码:
1 | while ((victim = unsorted_chunks (av)->bk) != unsorted_chunks (av)) |
malloc 的时候会遍历 unsortedbin 且把他们都分配到该分配的地方去(切割分配,exact fit,smallbin,largebin),这个过程会不断解链,把尾节点(对于循环链表这么说不太准确)放到该放的 bin 里去,然后把倒数第二个节点bck链接成一个新的环。
而 bck = victim->bk; 也就是只依赖 bk 来判断谁是现在的倒数第二个 chunk 。
如果我们伪造一个 bk 指向我们希望的地址-0x10作为伪造的 chunk ,那么这个 chunk 就会被当作倒数第二个节点和 bin 的头链接成循环链表。
攻击
具体攻击就如下图这样:
先塞一个 chunk0 ,然后更改 bk 指向fake_chunk,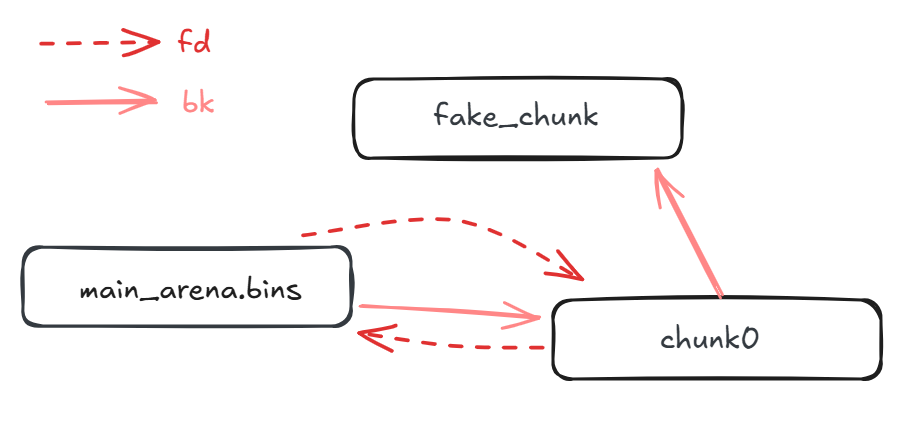
然后malloc一下,就会进入遍历 unsortedbbin 的环节,此时 fake_chunk 被认为是bck, 根据先进先出,chunk0 将从 unsortedbin 中被拿出,然后执行那两句unsortedbin attack的代码,可以看到有两条指针有变化,蓝色的就是我们期待的攻击结果,此时fake_chunk的fd指针位置被改成了一个大数。
(以满足exact fit时为例,其他也差不多)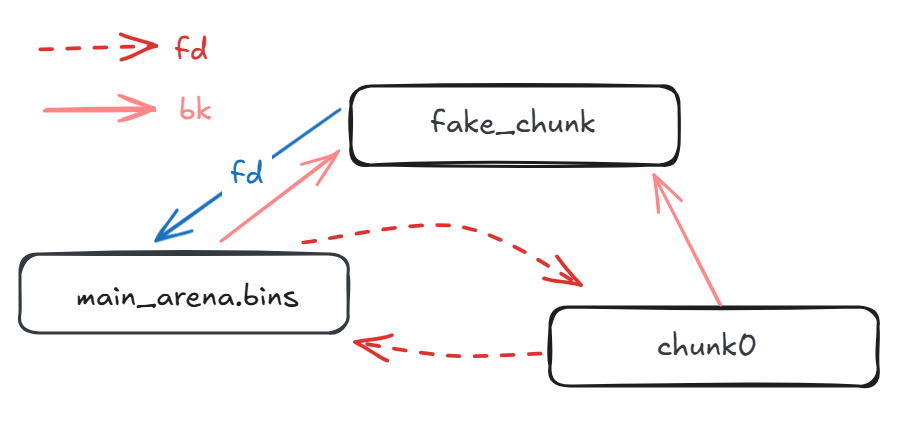
不过在libc2.28及之后
这里的源码变成了:
1 | /* remove from unsorted list */ |
因为有了安全性检查,所以 unsortedbin attack 失效了,不过如果要是能泄露堆地址以及堆溢出可以改写很多的话或许还是可以绕过的。
largebin attack
先是 largebin 结构的介绍:
large bin链表总共有63个链表
bins 中占据 64 到 126 这个范围的位置
| index | 范围 |
|---|---|
| 64 | [0x400,0x440) |
| 65 | [0x440,0x480) |
| … | … |
| 126 | >0x40000 |
每个 bin 内部管理一段范围大小的 chunk,bin 的公差也并补固定,从0x40逐渐增大。
有关公差的设计,遵循下面这个表格:
| 组 | 数量 | 差值 |
|---|---|---|
| 1 | 32 | 64(0x40) |
| 2 | 16 | 512(0x200) |
| 3 | 8 | 4096(0x1000) |
| 4 | 4 | 32768(0x8000) |
| 5 | 2 | 262144(0x40000) |
| 6 | 1 | 无限制 |
在每个 bin 管理的内部,fd,bk指针仍然指向同样大小的 chunk ,而不同大小的 chunk 通过 fd_nextsize,bk_nextsize链接,并且fd_nextsize,bk_nextsize实际上管理的是一套双向循环链表。这套链表内是每个不同大小但 size 满足同一个 largebin 的 第一个放入 largebin 的 chunk。
把fd_nextsize,bk_nextsize指针去掉来看,整个链表又被fd,bk链接成一套双向循环链表。这套链表管理的是所有放入 largebin 的 chunk ,以及 bin 头。
所以fd_nextsize,bk_nextsize也可以看成是一套跳表,比起只有fd,bk的情况,更快的找到指定大小的 chunk 。
fd,fd_nextsize总指向更小的chunk,bk,bk_nextsize总指向更大的 chunk。
再是一坨 malloc 分配 largebin 源码
1 | else |
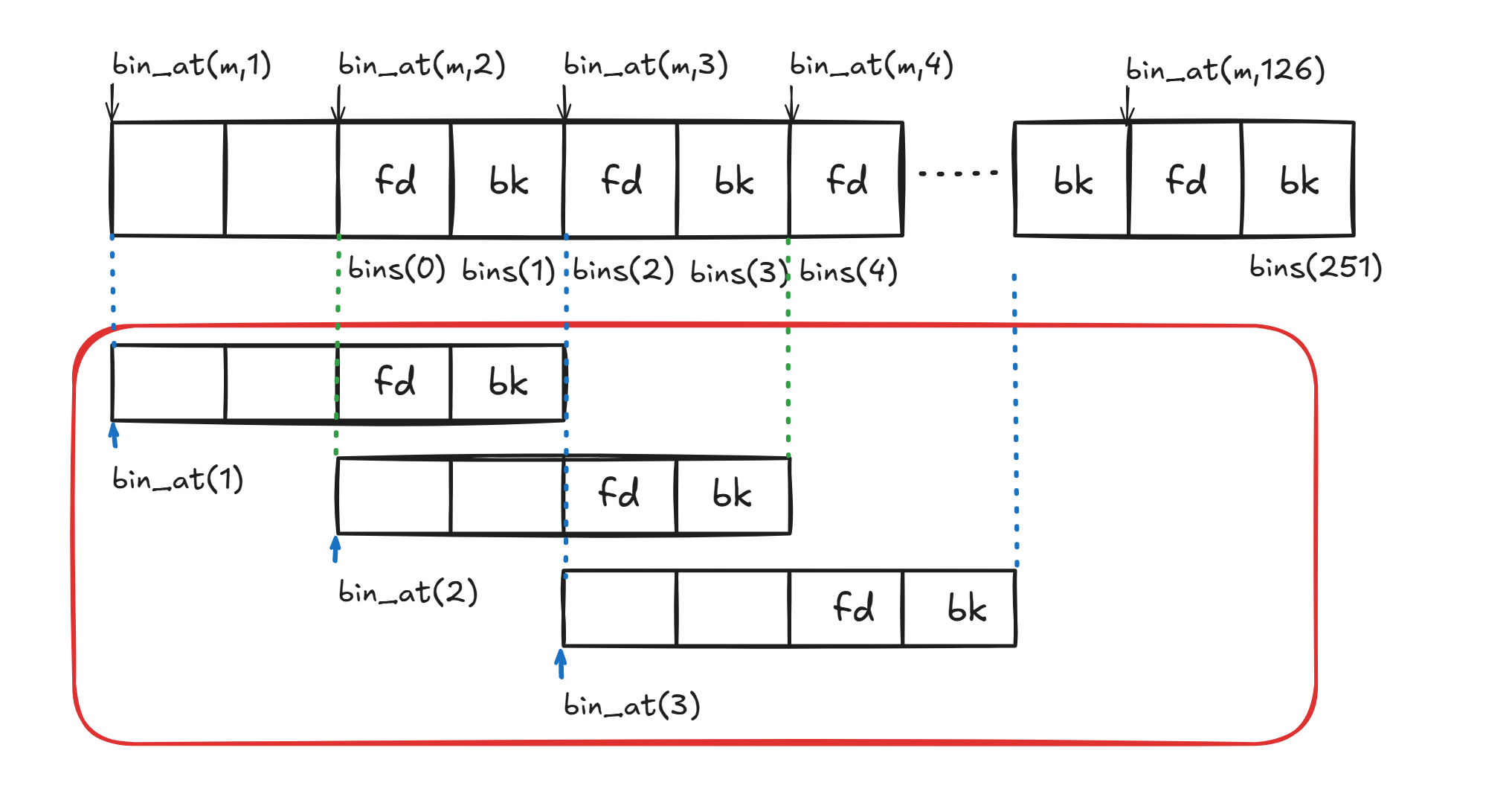
从bin_at开始讲起
其实这和利用的部分没什么关系,只是在了解后觉得这种省空间的方式很有趣。
数组中的 bin 依次如下
- unsorted bin 的索引为1。
- 索引为 2-63 的是 small bin,同一个 small bin 链表中的 chunk 的大小相同。两个相邻索引的 small bin 链表中的 chunk 大小相差的字节数为 2 个机器字长,即 32 位相差 8 字节,64 位相差 16 字节。
- 索引为 63-126 的是 large bins。large bins 中的每一个 bin 都包含一定范围内的 chunk,其中的 chunk 按 fd 指针的顺序从大到小排列。相同大小的 chunk 同样按照最近使用顺序排列。
而这一块 bin 就放在 arena 中。
bin_at宏定义源码
1 |
m 代表的是分配区的地址,配合上不同类型的 bins 的索引就可以找到每个 bin 链表的头。bin_at 的作用就是通过不同 bin 的索引找到链表头。
通过这样的计算就能将对应的 bins() 再往前移两个单元的长度,也就是人为往前移出了prev_size位和size位。
(图中bins(0),bins(1)即为 unsortedbin 的 fd,bk)
对于 bin 的链表头来说,其实prev_size与size也不是很重要,于是只是把得到的结果强行转化为malloc_chunk*类型,可以有正常的链表链接操作,而实际在内存上并不是 malloc_chunk 结构体。
源码分析
注意上文中注释//largebin attack 1-2的部分,
1 | else |
进入这里的 else 的情况是:
- largebin 非空
- victim 不是 largebin 中最小的堆块
- victim 的 size 和原 chunk 大小不相等。
这段的本意就是插入fd_nextsize,bk_nextsize链接的跳表中,但是因为没有检查 fwd 的 bk_nextsize 是否被更改,所以如果提前更改 fwd 的 bk_nextsize 那么也能塞出一条指针
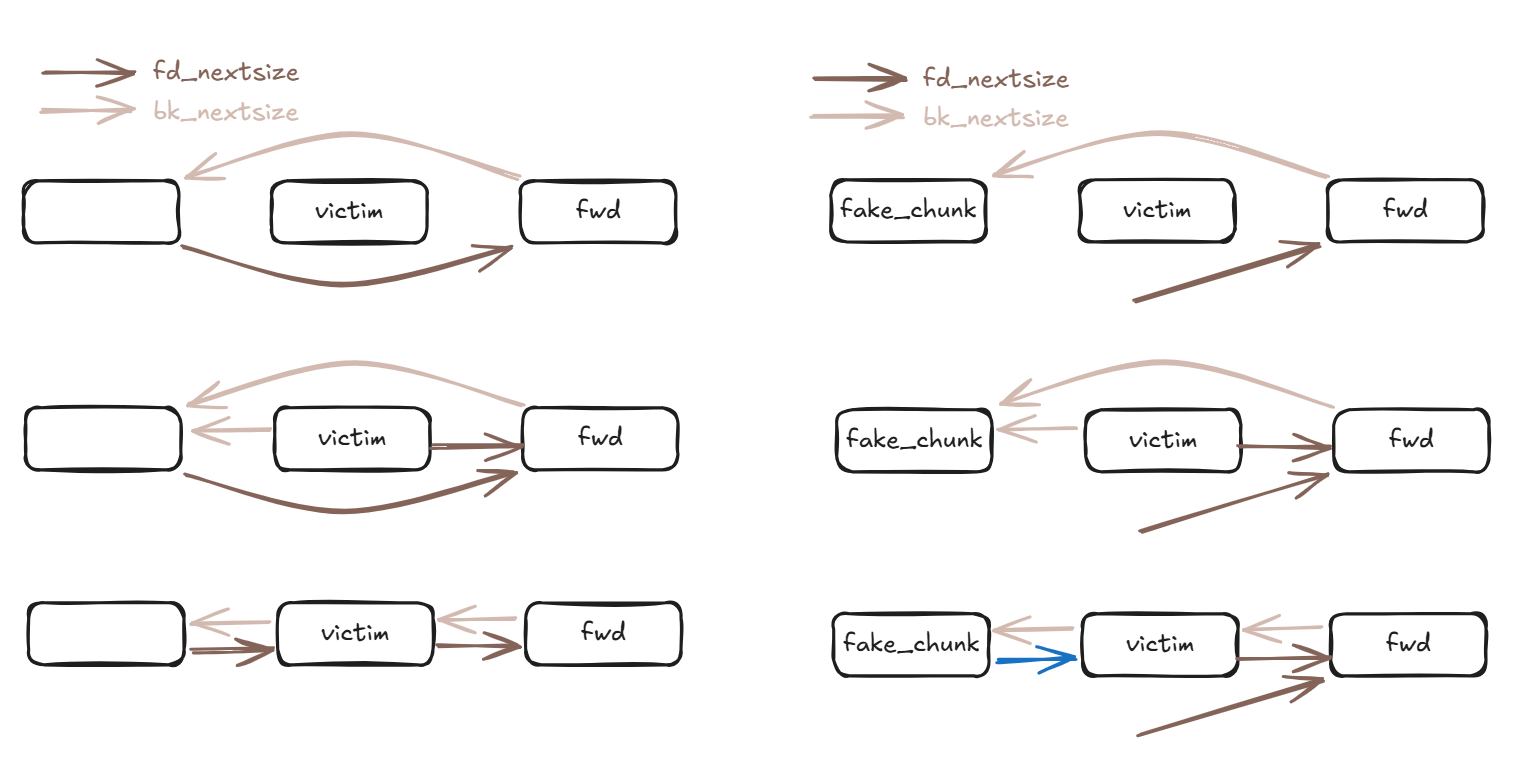
(左为正常插入流程,右为伪造 bk_nextsize)
同理,当 victim 是 largebin 中最小的堆块时,则会走向//largebin attack 1-1,一样是在循环链表插入的时候发生
又同理,//largebin attack 2的地方也是伪造了 bk 。
攻击
在老版本下,我们有两条路径(即选择//largebin attack 1-1还是//largebin attack 1-2),最多两个位置可以修改
不过修改的都是bk_nextsize与bk,造成 target_chunk 处 fd_nextsize与 fd 的链接错误。
最经典的 poc 就是 how2heap 的演示,选择走//largebin attack 1-2 + //largebin attack 2
这里不过多赘述具体操作,大致思想是:
- 向 largebin 中放入一个 chunk1 ,同时在 unsortedbin 里预备一个大于 largebin 的 chunk2。
- 修改 chunk1 的
bk_nextsize为target_chunk-0x20,bk为target_chunk-0x10 - malloc一个堆块,触发 unsortedbin 整理机制,chunk2 链入 largebin,完成攻击。
libc-2.31
然而同样的,在libc2.30及之后,largebin也加入了相应的校验。
1 | else{ |
那么现在
对于第一个检查: victim 不是 largebin 中最小的堆块时不能随意更改 bk_nextsize,//largebin attack 1-2失效。
对于第二个检查:bk 的位置无法随意更改了,//largebin attack 2失效。
所幸,//largebin attack 1-1仍然保留
攻击
题目:hgame2024 week3 Elden Ring III
- 向 largebin 中放入一个 chunk1 ,同时在 unsortedbin 里预备一个小于 largebin 的 chunk2。
- 修改 chunk1 的
bk_nextsize为target_chunk-0x20, - malloc一个堆块,触发 unsortedbin 整理机制,chunk2 链入 largebin,完成攻击。
(づ′▽`)づ
后记
迟到了非常久,久到我有点忘记了为什么要把他们写在一起,可能是因为都是双向链表,然后都是任意地址非任意写,只是改大数。暑假没写是因为真的要忘光了,然后刚回忆起来一点就又去忙干别的事。总之希望这篇能够讲清楚这两种利用,变成未来的记忆胶囊((。
后后后记:没讲清楚,之后又回来补充了一些东西
- Title: 图解unsortedbin attack & largebin attack
- Author: M1aoo0bin
- Created at : 2024-07-23 22:21:52
- Updated at : 2024-12-04 11:26:00
- Link: https://redefine.ohevan.com/2024/07/23/really-ez-largebin/
- License: This work is licensed under CC BY-NC-SA 4.0.