d3image出题手记

_φ_(..)
d3image
题目描述
我一定是训练模型训练出了幻觉,怎么从这张图里看出了“不存在”的文字?
I must be hallucinating— how am I seeing ‘nonexistent’ text in this image?

题目源文件
code出题历程
AI 有太多地方值得探索,也并不安全。但是受限于平台负载,服务器,运算能力和怎么藏flag等等因素,AI 类型的题目在 CTF 中很难做到恰当的呈现。
由于有过一段视觉的经历,所以对相关任务的训练时长等细节还算了解,就想着在自己还能把握的范围内出这么一道题目。
在取材的时候复现了三篇论文,分别时间来自19,21,25年,本意是为了使题目不要太老套,但最后因为25年的文章的实验数据没有足够清晰的给出等原因,最后反而取材了前两篇文章。
在使用模型进行图片隐写的问题上,主要有两个难点:
- 把信息合理的嵌入到图片中而不被发现
- 有一个合适的解码器能够正确的还原信息
使我感到意外的是,第一点在实现上反而难于第二点。从实验结果来看,为了处理第一点往往需要各种精心与专门的设计,而至于第二点,哪怕是简单的卷积网络配合上足够多的训练数据,也能够达到不错的效果(指 98% 以上的精确度)。当然,第二点的容易实现也离不开我们想要隐写的是二进制数据,看上去 0/1 很难匹配,且丢失一位的成本很高。但事实上对于前者,隐写二进制数据流的二分任务一定比隐写图像的拟合任务简单;至于后者,通过极高的精确度加上校验码也可以很好的缓解。
但把信息合理嵌入到图片中这件事,三篇文章都使用了不同的方式。19年的文章尽管增加了一个判别器,但事实上生成相似的隐写图像并不是由这个判别器起作用(我在尝试删去这个结构后得出了这样的结论),而主要是依赖于编码网络的最后一步将做完变换的张量与原图进行加运算;21年的文章则是本身酒吧隐写的部分一开始就控制在肉眼不易认为发生变化的小波区域;25年的文章结构与19年的很像,也非常凑巧的,判别器没有起到足够大的作用,图像质量会随着训练进程不断降低,而解密网络的精确率却随之升高,尽管他们中间确实存在一个轮次有相对完美的效果。
预期解
此题的预期解是选手能够意识对网络模型进行逆向建模,只需要正确写出反向的网络与运算规则,把题目给出的模型加载进新的框架即可得到flag。
在这样的情况下,选手端需要的资源并不多,仅需满足以下环境:
- Python 解释器版本需与题目要求的 PyTorch 版本匹配
- 其余缺失库选择pip默认安装版本即可
- cuda并非必须的,你可以把所有的张量都移动到cpu上运算。
在收到的 wp 中,很高兴大部分选手都使用了正确的思路,下面详细的解释一下这个思路的实现与可行性。
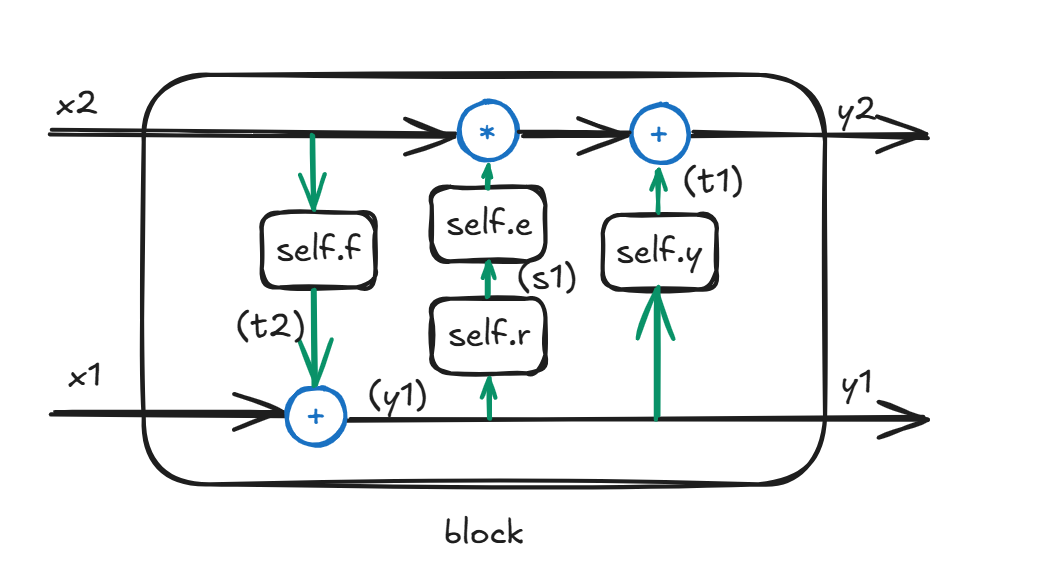
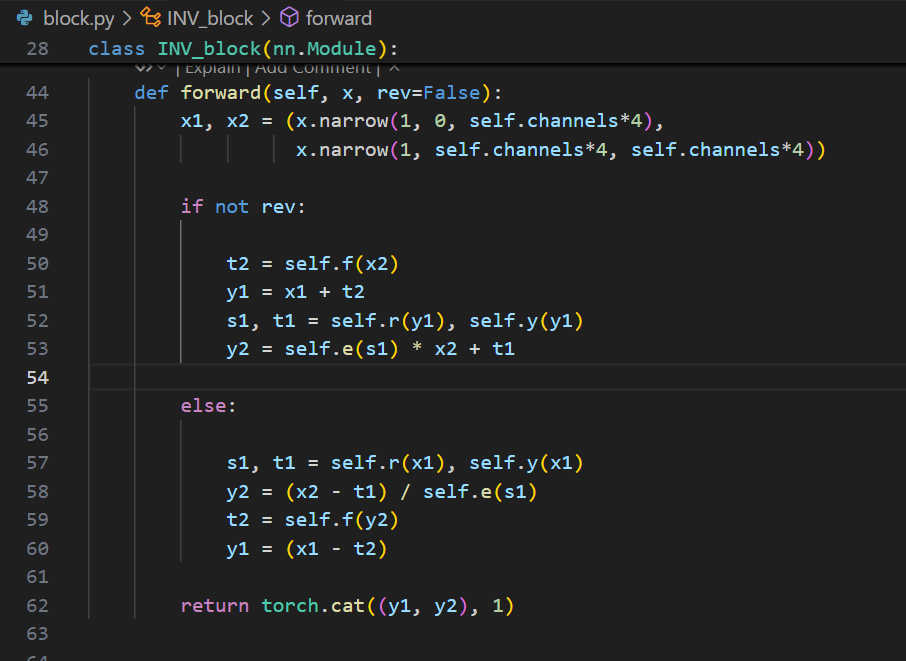
首先,分析网络框架: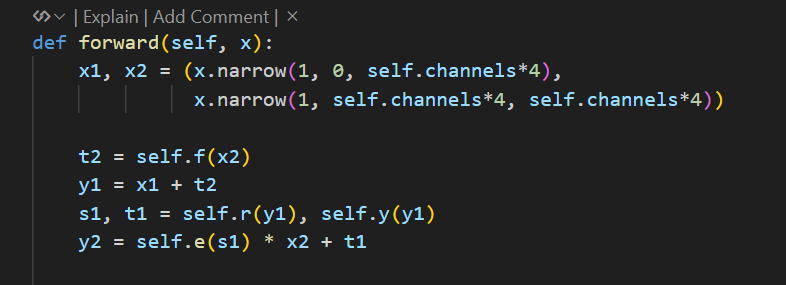
每个block大致如上图,标注的文字信息与代码截图对应。
- 蓝色部分:基础张量运算(均存在数学逆运算);
- 绿色箭头:输入输出变换(方向固定,不可逆);
- 黑色箭头:可逆运算路径。
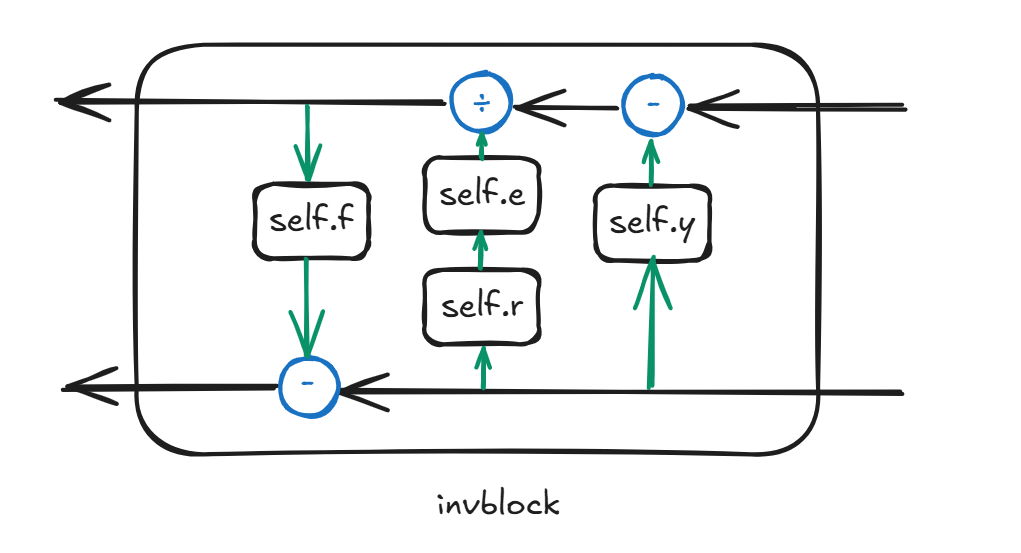
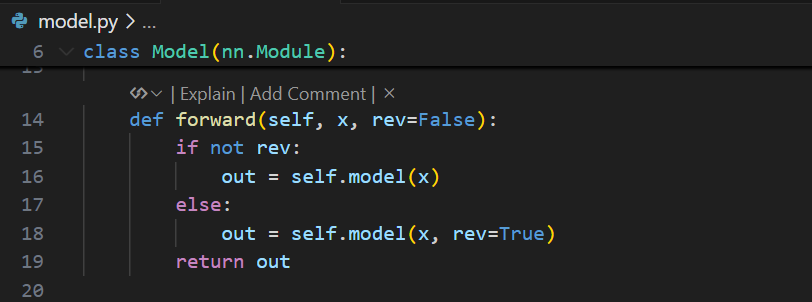
根据如上思路,我们只需要在 model.py,d3net.py 和 block.py 中作如下修改即可:
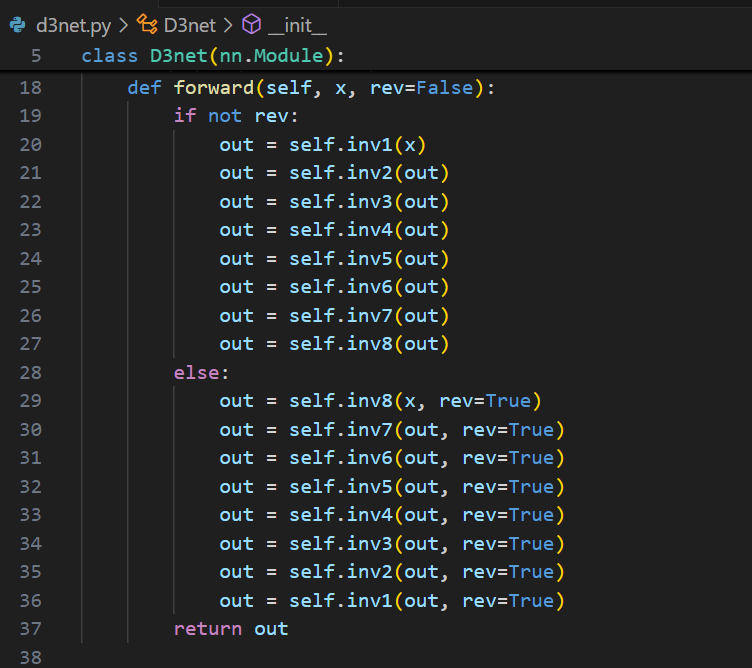
其次,dwt 与 iwt 在图像处理中本身就互为一对逆运算。
最后,逆向网络还需要 y2 ,在题目附件中提供了一个名为 auxiliary_variable 的函数来辅助完成。经实验与数学验证,y2 可为任意与 y1 同形状的张量,不影响最终结果。
修改后的decode如下:
1 | def decode(steg): |
预期中的非预期解
当然,由于这道题的定位是趣味,所以在这种需要看出可逆向的结构之外,亦可基于以下方法求解(力大砖飞需更高算力,但笔记本电脑可胜任):
具体做法是,选手自行选一个图像数据集,通过题目模型加密生成“密文-明文”配对数据;然后以加密数据为输入,原始数据为标签,训练一个自定义解密模型。
这个方法的可行性在于,由于题目最终输出为二进制形式,解密问题被简化为二分类任务,再加上校验码可以降低对最后精确度的要求,所以对解密网络的训练难度与网络深度要求大大降低。
如果题目是把图片隐写到图片里,那么训练一个解密网络的难度将会大大增加,因为本意只是想在一天内给选手们一个有趣的简单轻量AI题,专注在网络本身,而不是演变为算力比拼或者过于脑电波,所以在任务上没有继续加深难度,也给出了大部分的代码。
非常遗憾也因为题目代码量较小,选手可以使用 AI 来理解工程代码,并快速的得到解答。但还是希望选手能够从中感受到题目本身“不需要训练 AI 的 AI 题”的趣味性。
参考:
HiNet: Deep Image Hiding by Invertible Network
SteganoGAN: High Capacity Image Steganography with GANs
- Title: d3image出题手记
- Author: M1aoo0bin
- Created at : 2025-06-02 21:35:53
- Updated at : 2025-06-08 15:15:30
- Link: https://redefine.ohevan.com/2025/06/02/d3image/
- License: This work is licensed under CC BY-NC-SA 4.0.